CNN Components for Medical Imaging: What Kernels, Pooling, and Receptive Fields Actually Do
A primer on the four CNN primitives — kernels, conv layers, pooling, receptive fields — grounded in real activations and Grad-CAMs from a chest X-ray classifier.
A convolutional neural network is a stack of learned local filters. Each filter scans its input for a specific pattern and outputs a map of where that pattern appeared. Layers stack so deeper filters compose patterns from earlier ones, and spatial resolution is reduced between stages so a neuron near the top of the network sees a much larger region of the input than one near the bottom.
The rest of this post is what each piece — kernels, conv layers, pooling, receptive fields — actually does on a chest X-ray, and what happens when one of them doesn't fit your problem.
Why convolutions exist
A 224×224 grayscale image has roughly 50,000 pixels. Send it through one fully-connected layer with 1,024 hidden units and you've burned 50 million weights — absurd, and the wrong inductive bias besides. Useful pixel correlations in images are mostly local: a rib edge is defined by a few neighboring pixels, not by the top-left corner and the bottom-right.
Convolutions encode three priors that match images well:
- Locality. Each output depends only on a small neighborhood of the input.
- Weight sharing. The same filter applies everywhere. A consolidation in the right upper lobe and one in the left lower lobe activate the same feature detector — the network doesn't relearn "consolidation" separately for every pixel position.
- Translation equivariance. Shift the input and the feature map shifts the same way.
Throughout this post we'll come back to one pediatric chest radiograph from the Kermany et al. (2018) pneumonia dataset:
The model is a ResNet50 pretrained on ImageNet with the final layer swapped for a 2-class head and fine-tuned for 10 epochs. Test accuracy 89.7% — a teaching example, not a clinical one.
The mechanics
Kernels
A 3×3 kernel is nine numbers. The convolution operation slides it across the image, multiplying each kernel value by the corresponding input pixel and summing, producing one output value per position. With padding, the output is the same size as the input.
The clearest way to see what convolution computes is with a hand-designed kernel. Here is a Sobel-x kernel — positive values on the right, negative on the left — applied to a chest radiograph:
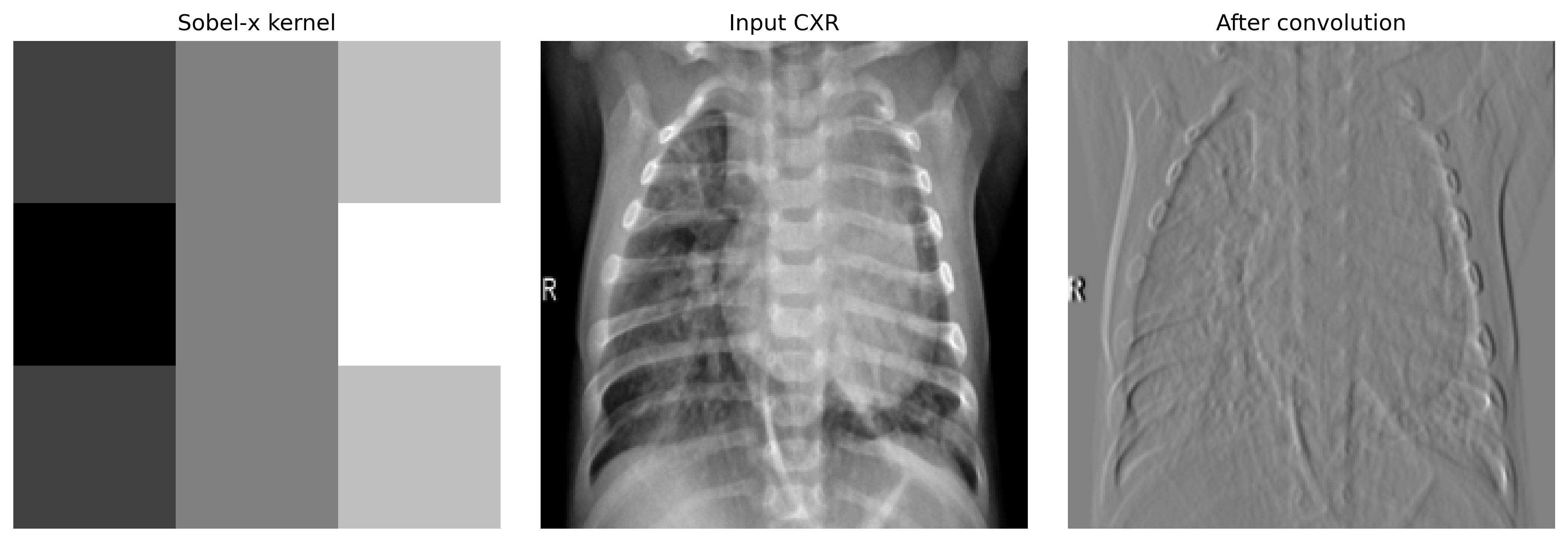
Notice the marker. The Sobel kernel doesn't care that "R" is an annotation rather than anatomy — it responds to whatever edges exist. Learned kernels inherit the same property, and we'll come back to it.
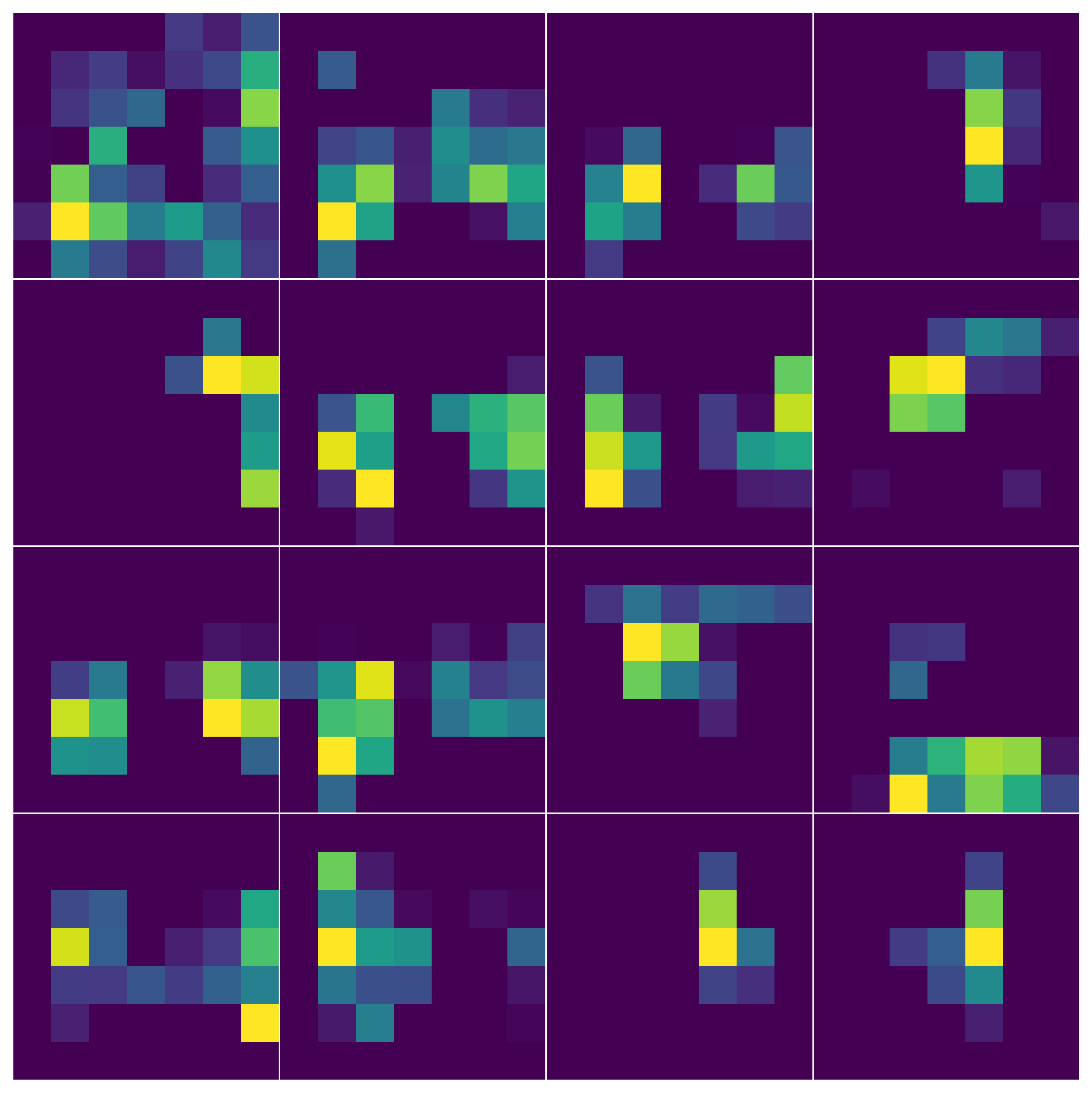
Early-layer learned kernels typically look like edge, color, and gradient detectors. Deeper layers compose these into textures, parts, and eventually full anatomical structures.
Conv layers
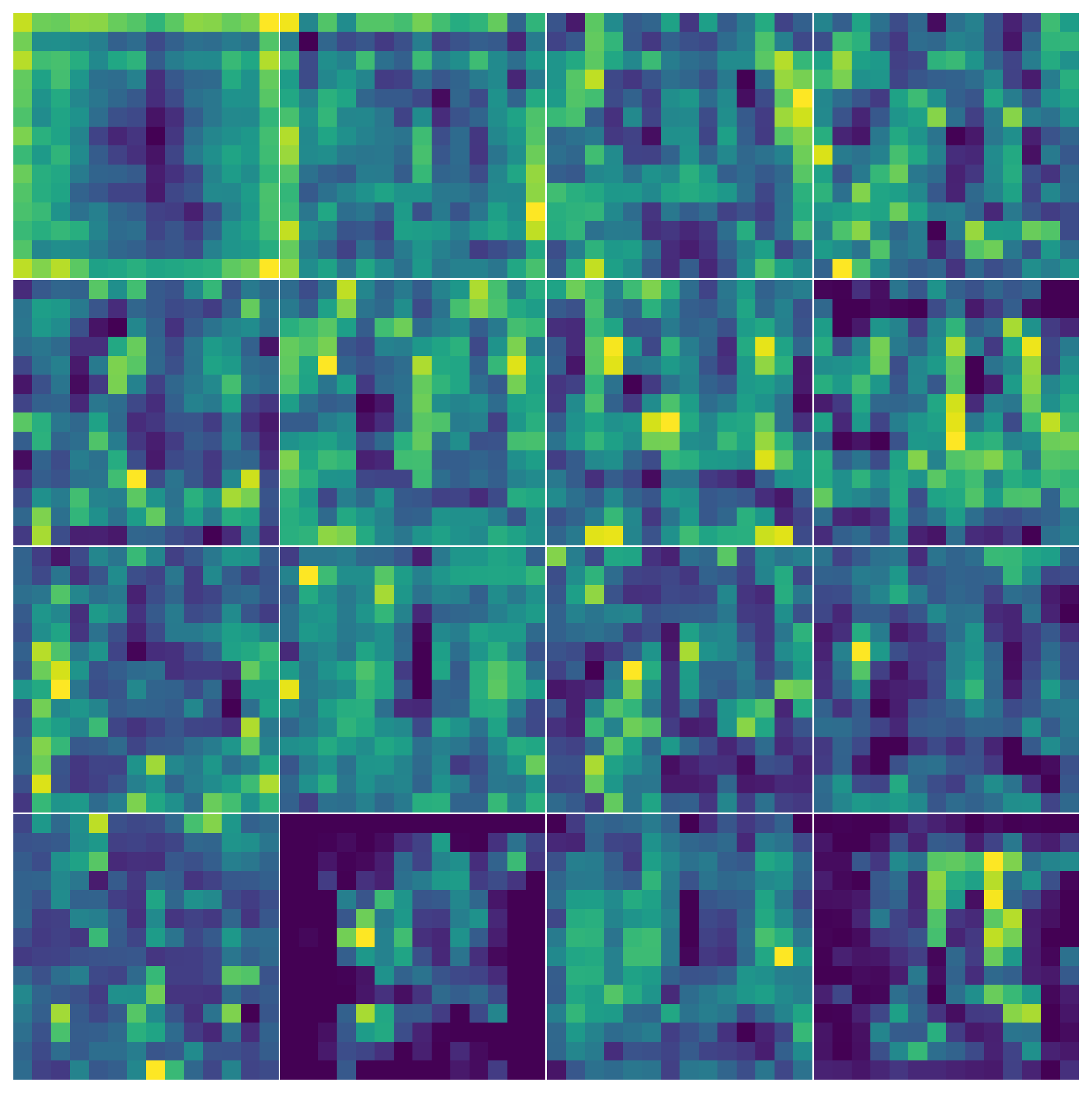
A conv layer applies many kernels in parallel, each producing one output channel. ResNet50's first conv layer has 64 kernels of size 7×7. Here is what they look like after ImageNet pretraining:

And here are the same kernels after fine-tuning for 10 epochs on the pneumonia dataset:

They look identical because they essentially are. Early-layer features — edges, blobs, gradients — are general. They don't need to change much when you transfer between domains. The work of adapting to medical imaging happens deeper in the network. This is also why almost every production CXR system initializes from ImageNet weights rather than training from scratch.
You can watch abstraction grow with depth by reading off activations at three layers of the same model on the same input:
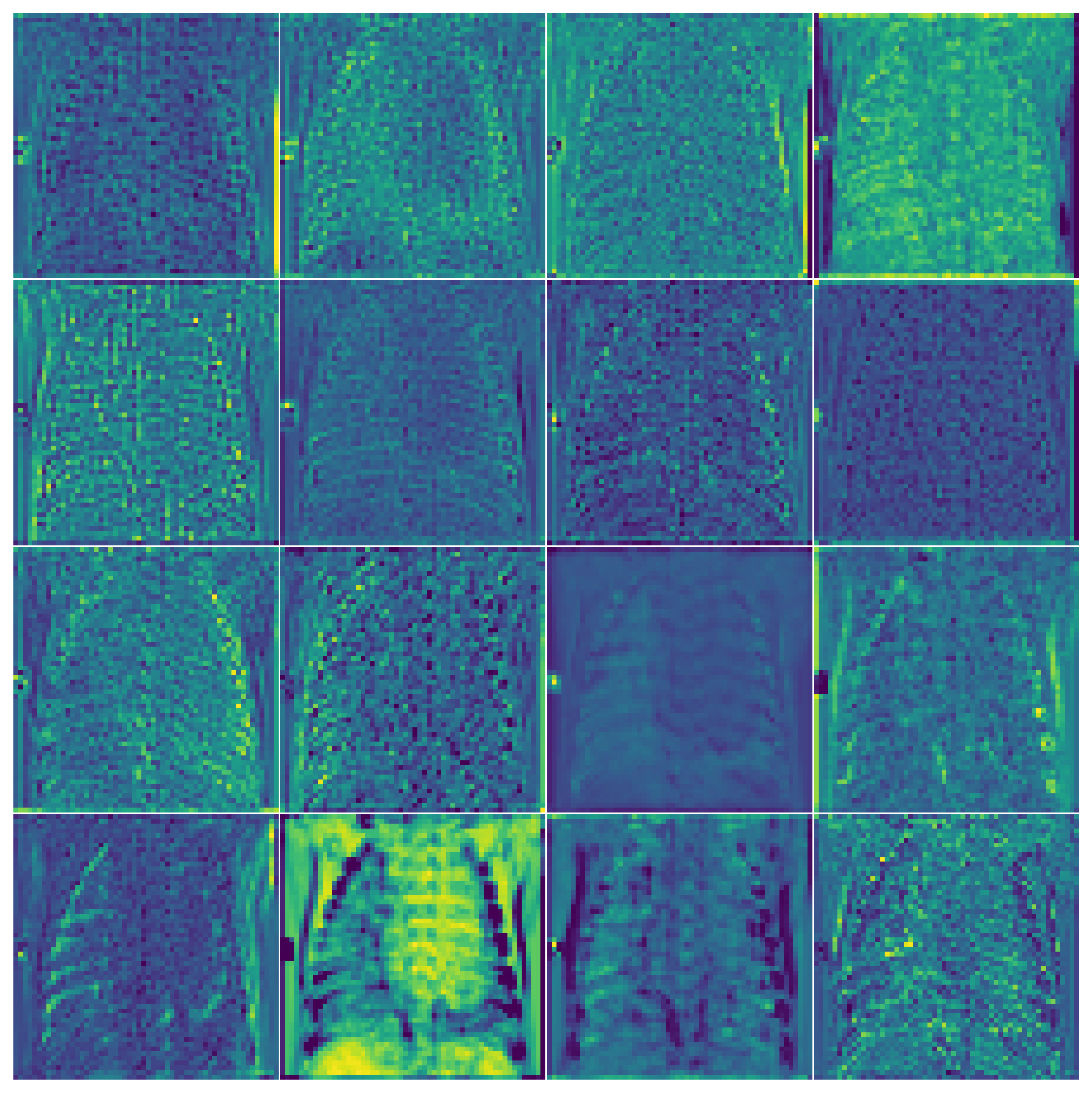
Pooling
Pooling reduces the spatial size of a feature map. We do it for three reasons: to reduce compute, to give the network a small amount of translation invariance, and to force later layers to summarize rather than enumerate.
Max-pool takes the maximum activation in each window. Avg-pool takes the average. They preserve different things:
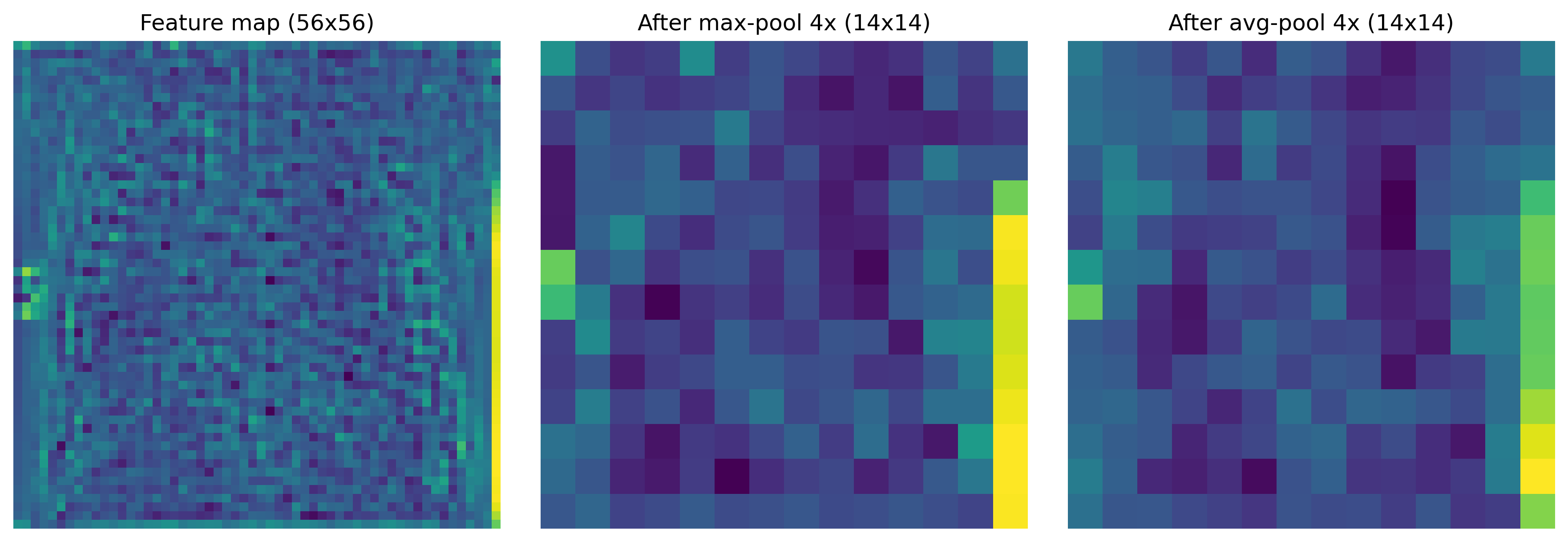
Max is the default in classification CNNs because pathology signals are often peaky — a bright opacity against dark lung field, a thin fracture line against bone — and avg can wash those out. The cost: anything subtler than the pool window vanishes. A 2-pixel-wide line in a 4×4 max-pool window survives if it is a strong edge and disappears if it is faint.
Receptive fields
The theoretical receptive field of a neuron is the region of the input image that can influence its value. At layer4 of ResNet50, this is essentially the entire image. But the effective receptive field — where the input actually has weight, measured as gradient magnitude with respect to input pixels — is much smaller and roughly Gaussian (Luo et al., 2016).
Here is the effective RF for a neuron at the center of three different layers, computed on the same input:
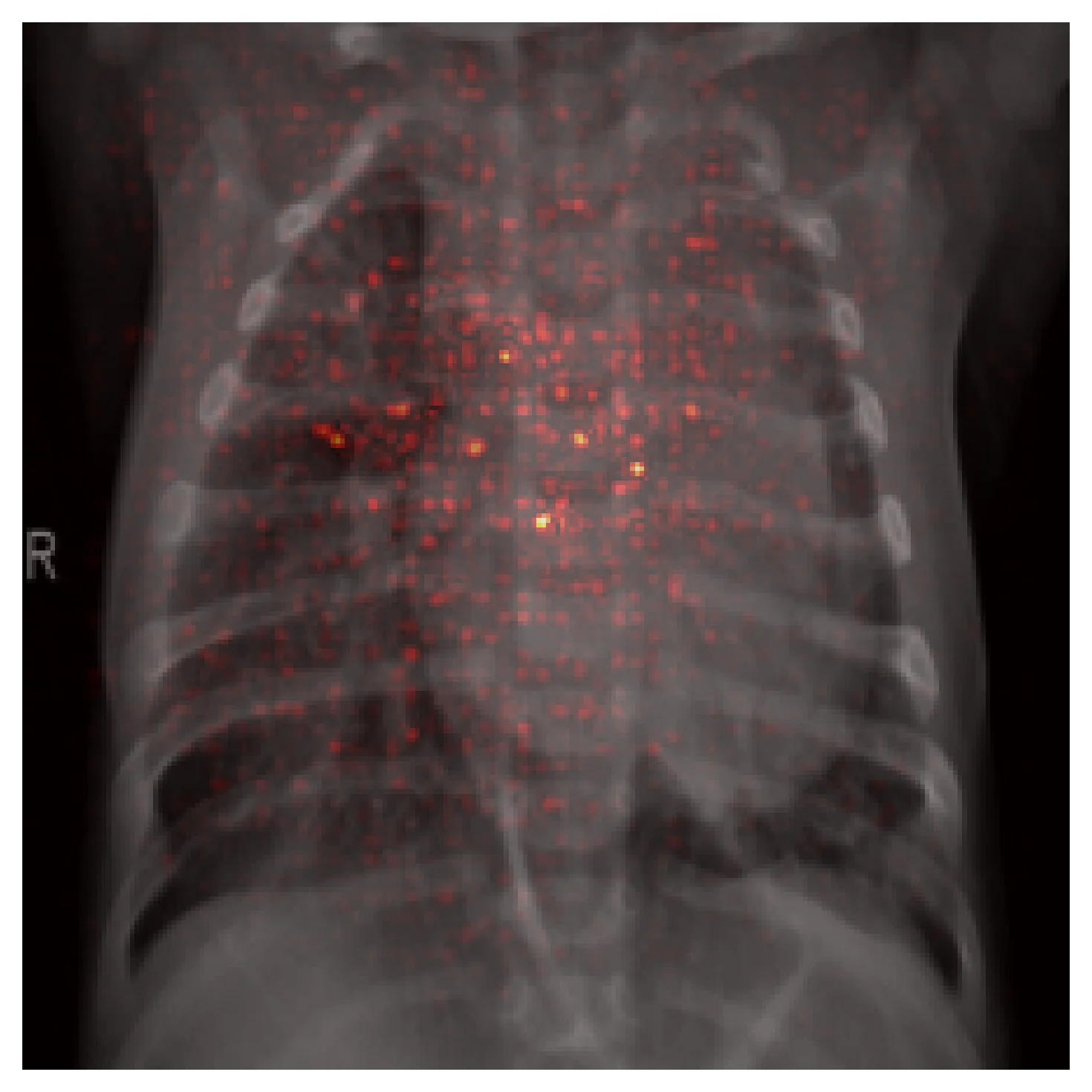
The practical consequence: if you are trying to detect findings smaller than the effective RF resolution at the layer you read features from, the signal is diluted by pooling before the classifier sees it. The standard fix is a feature pyramid (FPN, BiFPN) or a U-Net-style decoder, where you read from earlier, higher-resolution layers in parallel with the deeper ones.
Where it shines, where it breaks
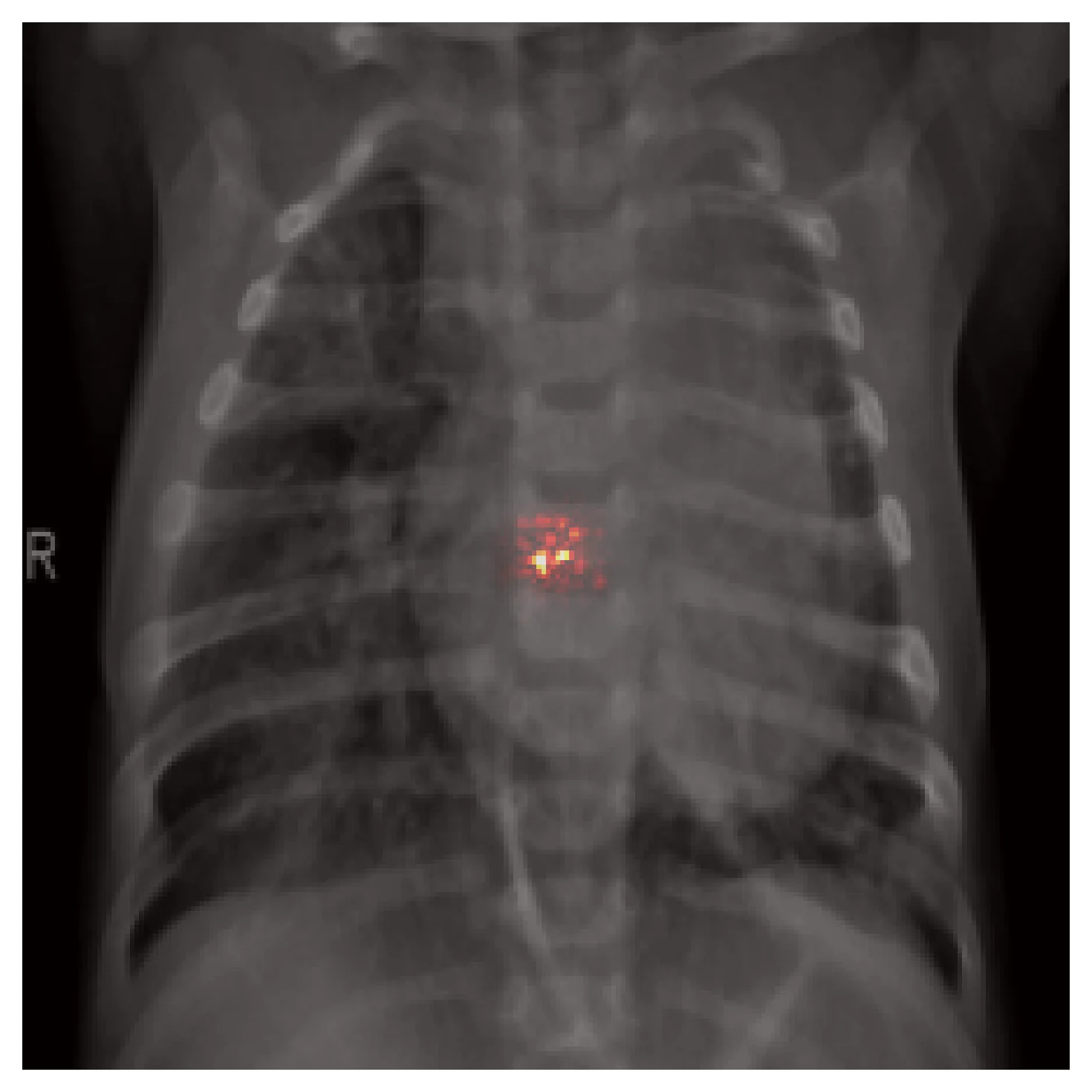
CNNs are excellent at locally-defined, texture-rich pathologies — consolidation, effusion, infiltrate. The inductive biases match the data. Here is Grad-CAM on the same input as above, with the model correctly classifying it as pneumonia:
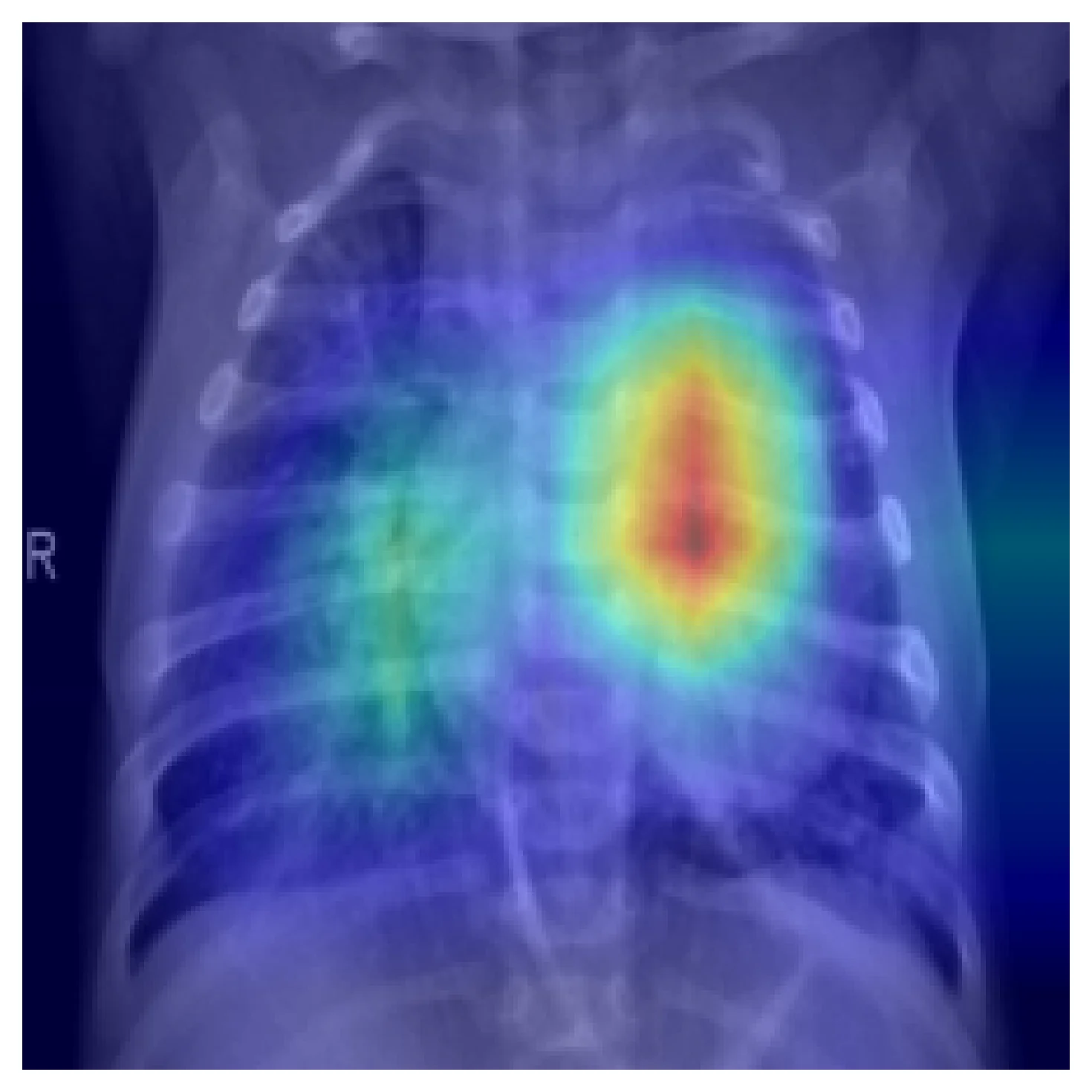
CNNs break in three predictable places.
Small findings. A hairline fracture, a small nodule, or a thin pneumothorax line can be a handful of pixels in the input. After several pooling stages, the signal is gone before the classifier sees it. The fixes are architectural — FPN, BiFPN, higher input resolution, segmentation heads on early layers — not hyperparameter tweaks.
Long-range reasoning. Cardiomegaly is defined by comparing heart silhouette to thoracic cavity width. Mediastinal shift requires comparing left and right hemithoraces. CNNs can do this only by stacking enough layers to span the spatial range; transformers can do it in one attention step. This is part of why ViTs and hybrid CNN-transformer models started showing up in medical imaging.
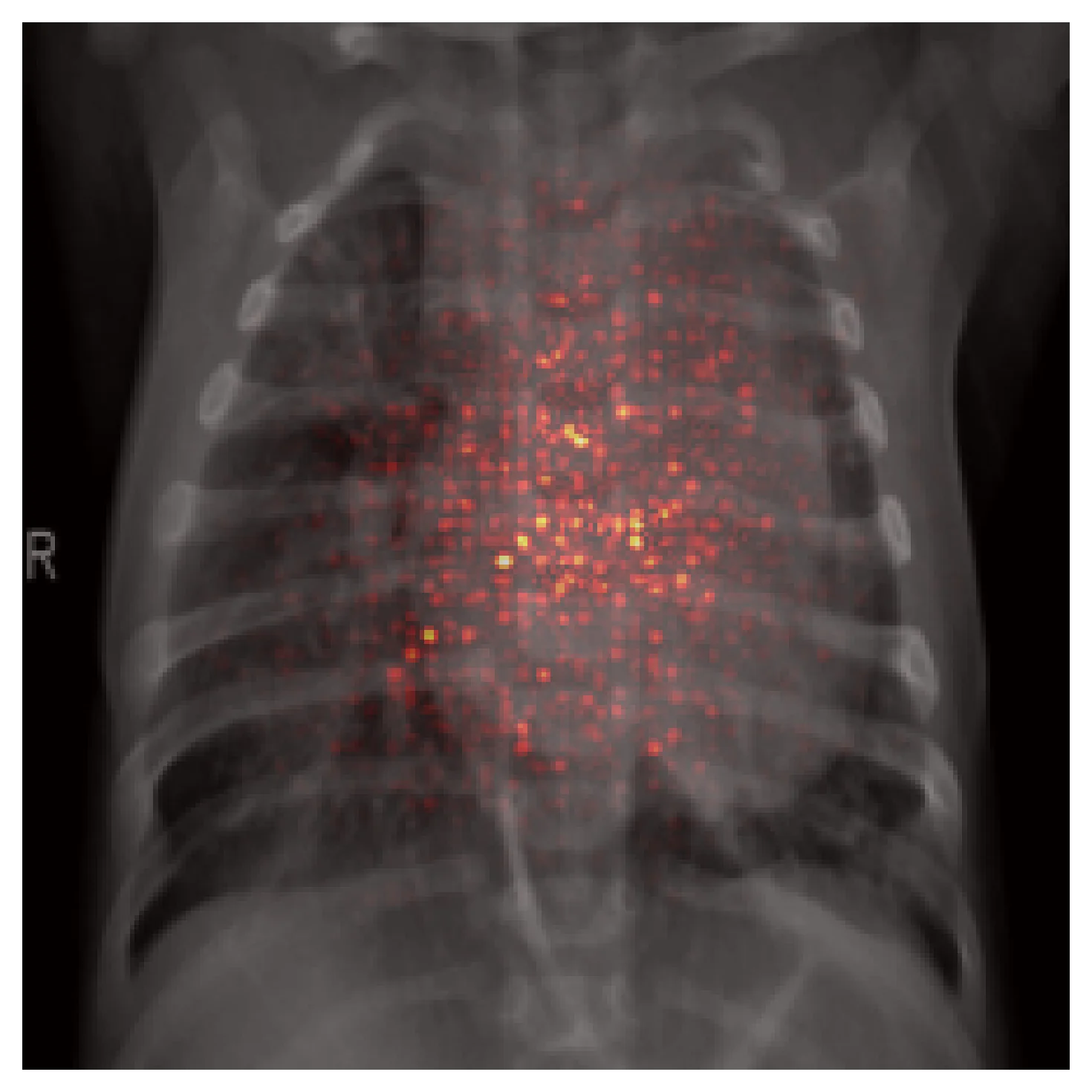
Shortcut learning. Trained on data with spurious correlations, a CNN will happily learn the shortcut instead of the pathology. Here is an example from the same model on a different correctly-classified pneumonia case:
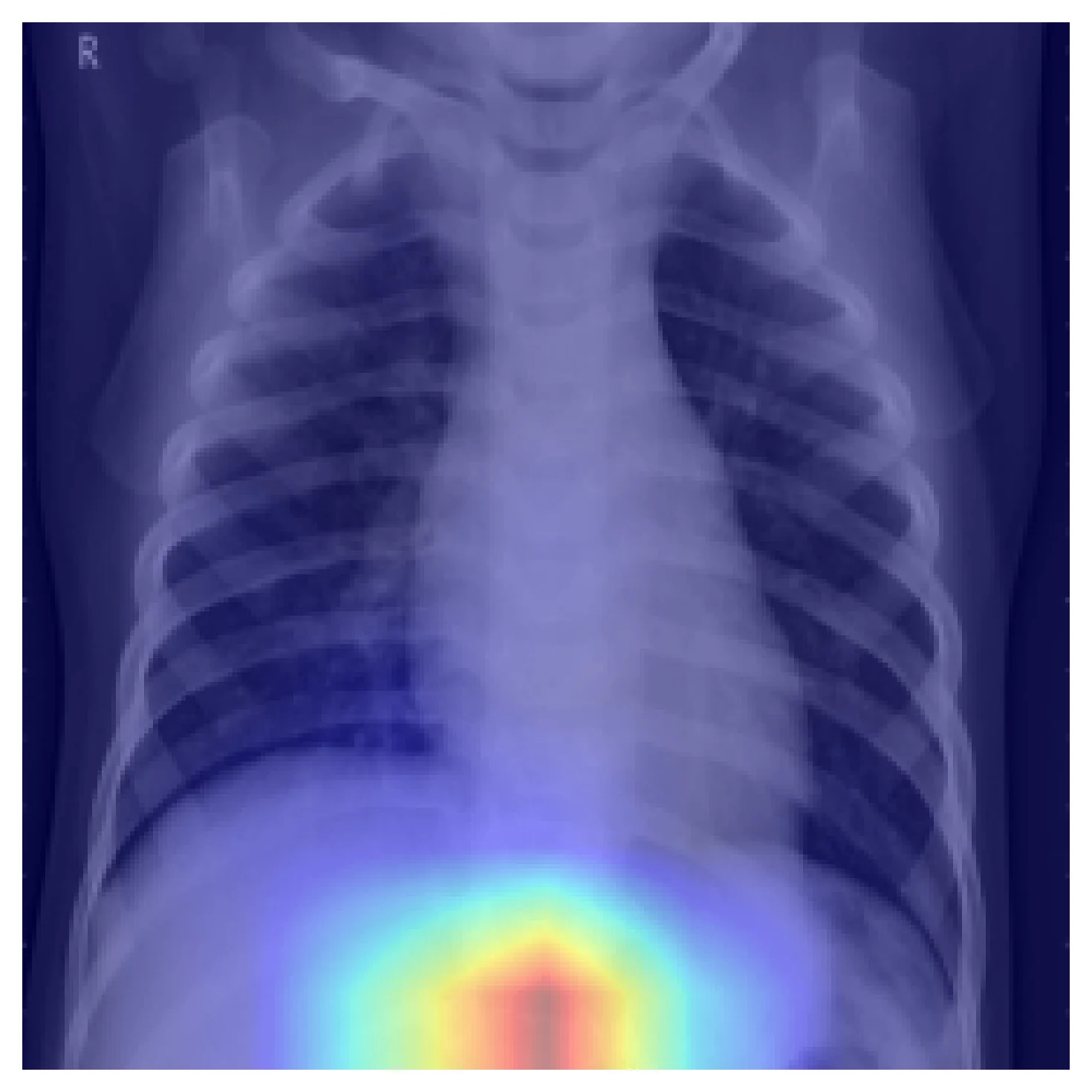
The prediction is right; the reasoning is wrong. Markers, tubes, exposure differences, side-letter tokens, even patient positioning can become shortcuts if they correlate with the label across the training set. A held-out split from the same distribution will not catch this — only attribution methods will, and only if you actually run them.
How this shows up in production medical-imaging engineering
Backbone selection rarely comes down to top-1 ImageNet accuracy. The relevant questions are whether the effective RF covers the finding size at the depth where the head reads features, how much input resolution you can afford, and which features need to be available at which scale.
Debugging matters at least as much as benchmarking. Two CNNs with identical test AUC can have wildly different attribution patterns. Grad-CAM is cheap; running it on a sample of test cases — especially errors — surfaces shortcut features that accuracy curves hide.
Small findings are an architecture problem, not a tuning problem. If pathology is smaller than the effective RF resolution at the layer you read from, no learning-rate schedule fixes that. Reach for feature pyramids, higher input resolution, or a detection-oriented architecture before tuning hyperparameters.
External validation is the honest measurement. Accuracy on a held-out split from the training distribution is a weaker signal than most teams treat it as. The first time a CXR model meets data from a different scanner, hospital, or patient population is usually the first time its real-world reliability is honestly measured.
Further reading
- Luo, W. et al. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. NeurIPS 2016. ERF is much smaller than the theoretical RF, and the difference matters in practice.
- Selvaraju, R. R. et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. ICCV 2017. The original Grad-CAM paper; short, readable, and the method is about thirty lines of PyTorch.
- Geirhos, R. et al. Shortcut Learning in Deep Neural Networks. Nature Machine Intelligence, 2020. Required reading for anyone deploying CNNs on medical data.