Feature Pyramid Networks for Medical Imaging: Why Detectors Stack Features at Five Scales
How FPN merges semantic-rich deep features with spatial-rich shallow ones, what the pyramid looks like on a chest X-ray, and where it doesn't save you from low input resolution.
A Feature Pyramid Network is a small extension on top of a CNN backbone that produces a stack of feature maps at multiple spatial resolutions from a single forward pass, with top-down connections so that higher-resolution feature maps inherit the semantic richness of deeper layers and deeper maps inherit the spatial precision of earlier layers.
It's the canonical answer to a question the CNN primer ended on: what do you do when the pathology you care about is smaller than the effective receptive field of the layer you read features from?
Why it exists
A CNN backbone's deeper layers know what things are — channels at ResNet50's layer4 respond to part-level and semantic concepts. But by layer4 the spatial resolution has dropped to roughly 7×7 from a 224×224 input. A 5-pixel nodule in the original image occupies less than one pixel at this depth. It's gone before the classifier sees it.
Shallow layers have the opposite problem. They preserve spatial detail (a 5-pixel nodule is still 5 pixels at layer1), but they don't know what a nodule looks like — channels at this depth respond to edges and textures, not concepts.
Detection from a single feature map forces you to choose. Early detectors like the original SSD attached prediction heads to multiple backbone stages independently, but the shallow stages had to learn semantics from scratch without the depth advantage. Performance on small objects suffered.
FPN's contribution: merge top-down. Start with the deepest features, upsample them, add them to the lateral features at the same spatial resolution before the merge. Repeat going down. You get feature maps at multiple resolutions, each enriched with semantic information from above.
Here is the chest X-ray we'll use throughout:
fasterrcnn_resnet50_fpn from torchvision, run in inference mode at 800×800 input. We're visualizing structure, not detection accuracy on CXR.The mechanics
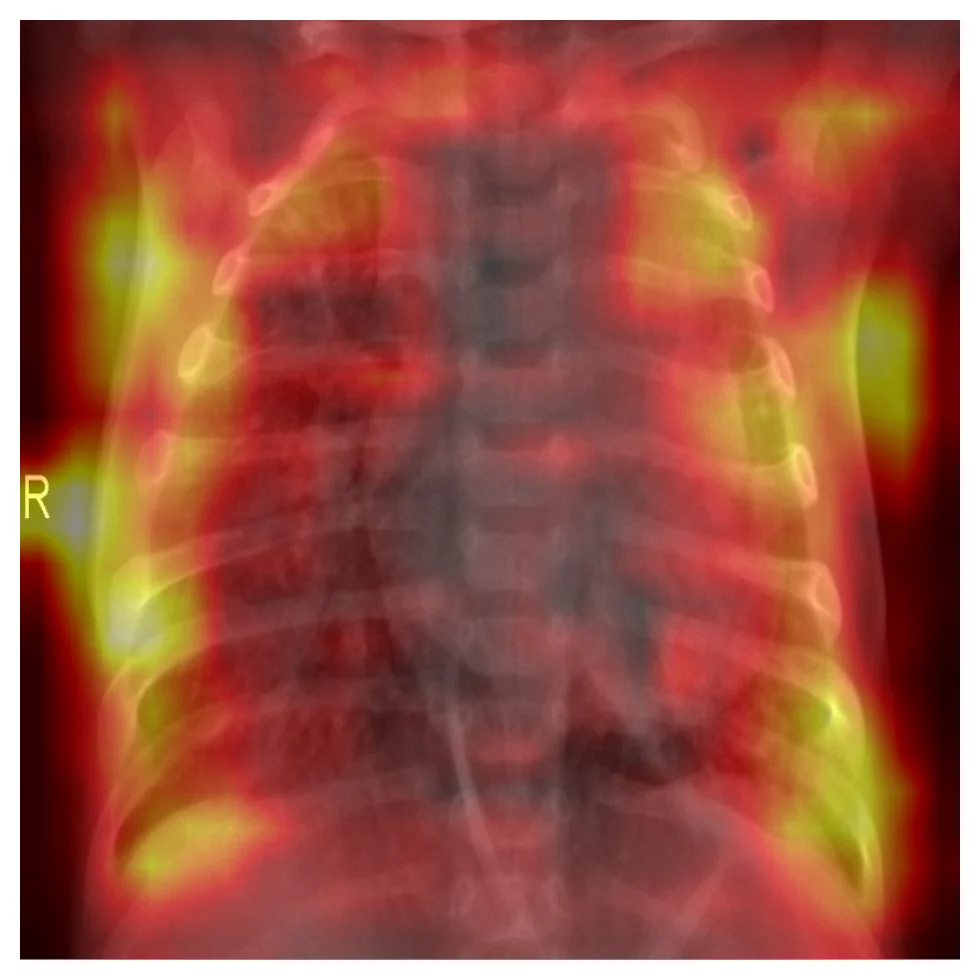
A ResNet50 backbone produces features at four stages — call them C2, C3, C4, C5 — at strides 4, 8, 16, 32 from the input. Channel counts grow: 256, 512, 1024, 2048. Here is C5, the deepest backbone feature, as a channel-mean heatmap on the input:
FPN turns C2–C5 into P2–P5 using three operations.
- Lateral 1×1 convs project each C-feature to a common channel dimension (256 for the torchvision default), so all pyramid levels have the same channel count.
- Top-down pathway. Start at the top: P5 is just C5 after the lateral projection. Then for each level going down, upsample the previous P-feature 2× and add it to the projected C-feature at the same resolution.
- Smoothing 3×3 convs after the merge, to reduce aliasing from the upsampling.
The result is a stack of feature maps, all 256 channels, at progressively higher spatial resolution. Most detectors add an extra block on top to extend the pyramid further. Faster R-CNN uses LastLevelMaxPool, which max-pools P5 to produce P6 — useful for detecting very large objects. RetinaNet and EfficientDet use LastLevelP6P7, which applies strided convs from C5 to produce P6 and P7.
Here is the full pyramid for the same input:

The same input now yields five feature maps. A detection head can attach to each level and look for objects at the size range that level is best at — small objects at P2 and P3, medium at P4, large at P5 and P6. This is the design that RetinaNet, Faster R-CNN, Mask R-CNN, and most modern detectors run on.
Variants worth knowing
PANet (Liu et al., 2018) adds a bottom-up path after the top-down one. The intuition: top-down delivers semantic info from deep to shallow, but spatial precision from shallow layers also needs to reach the deep ones for accurate localization. PANet is used in YOLOv4/v5 and several segmentation networks.
BiFPN (Tan et al., 2020, EfficientDet) generalizes further. Connections are weighted — each merge has learned scalar weights so the network can decide which input matters more. Connections are bidirectional, and the whole BiFPN block is repeated several times in sequence. The combination delivers better accuracy per FLOP than vanilla FPN; EfficientDet is the main argument for it.
For most CXR detection problems I've seen, vanilla FPN is sufficient. BiFPN earns its place when you have a fixed compute budget and want to push the pareto, which is essentially EfficientDet's pitch.
Where it shines, where it breaks
FPN works well on detection problems with multi-scale targets — large pathology that spans most of the chest cavity (cardiomegaly), medium findings (consolidation, effusion), and small ones (nodules, small fractures) all need to be picked up by the same network. A single feature map can't serve all three; a pyramid can.
It breaks in three predictable places.
First, FPN doesn't add information; it reorganizes it. The features at every level come from the same backbone forward pass. If the backbone wasn't trained to recognize lung nodules, no amount of pyramid magic produces them. FPN is a delivery mechanism, not a feature generator.
Second, input resolution composes with pyramid depth. Below is the same CXR run through the same model at four different input scales:

Third, shared-head detectors assume a fixed channel dimension. The torchvision default is 256, which is what makes a single detection head work across all five pyramid levels (the head doesn't need to know which level it's reading). Changing this cascades through the rest of the architecture.
How this shows up in production medical-imaging engineering
You almost never implement FPN yourself. It comes built into every modern detection model in torchvision, timm, mmdet, and ultralytics. Practical concerns are upstream and downstream of the FPN itself:
The level you read from determines what size range you detect. Anchor-based detectors assign scales by level explicitly; anchor-free detectors (FCOS, CenterNet) use level-wise regression bounds. Either way, you need to know which level your pathology should land at.
Input resolution is usually the bigger lever. If you train at 800×800 because that's the torchvision default but your findings are 10–20 pixels at native CXR resolution (1024–2048 px), increase the input size before changing the architecture.
BiFPN vs FPN is rarely the bottleneck for medical CXR work. The gains from input resolution, augmentation, and backbone choice typically dwarf the gains from swapping FPN topology. Try the simple thing first.
Further reading
- Lin, T.-Y. et al. Feature Pyramid Networks for Object Detection. CVPR 2017. The original. Short and figure-heavy.
- Liu, S. et al. Path Aggregation Network for Instance Segmentation. CVPR 2018. PANet — adds the bottom-up path.
- Tan, M. et al. EfficientDet: Scalable and Efficient Object Detection. CVPR 2020. Introduces BiFPN; argues for the weighted bidirectional design.