YOLO for Medical Imaging: How a Single-Stage Detector Sees a Chest X-ray
How YOLO predicts thousands of candidate boxes in one forward pass, what its three detection scales actually look like on a CXR, and what NMS does to clean up.
YOLO ("You Only Look Once") is a family of single-stage object detectors. Instead of first proposing regions of interest and then classifying them, YOLO predicts class scores, bounding-box coordinates, and an objectness score for every spatial position in a feature map, in one forward pass. Modern variants do this at three feature resolutions in parallel and merge the predictions through non-max suppression.
Why single-stage matters
A two-stage detector — Faster R-CNN being the canonical example — works in two phases. First a Region Proposal Network suggests roughly a thousand candidate boxes that might contain objects. Then a second-stage classifier scores each proposal. The architecture is modular and the high-end accuracy is competitive, but inference is slow and the deployment surface is bigger.
YOLO collapses both stages into one. The same convolutional backbone that extracts features also produces the final predictions, directly. There is no proposal step; every spatial location is a candidate. Inference is dramatically faster — modern YOLO variants run at 30+ FPS on modest GPUs — and the deployment surface is small: one ONNX export, one runtime call.
For medical imaging the calculus depends on the workload. Batch radiology analysis can afford Faster R-CNN. Real-time fluoroscopy, ultrasound landmark tracking, intraoperative guidance, or edge deployment on lab instruments cannot. YOLO is the right default whenever latency or deployment simplicity matters more than the top half-point of mAP.
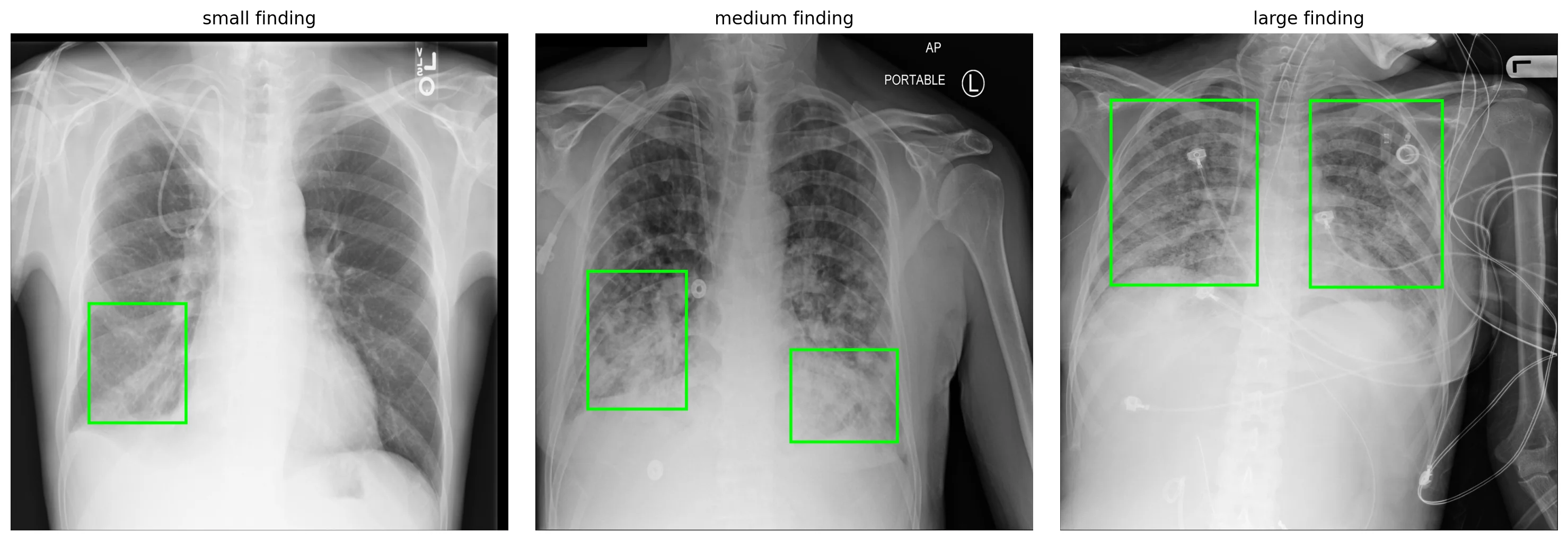
Throughout this post we'll work with a YOLOv8n model fine-tuned for 15 epochs on a balanced 3,000-image subset of the RSNA Pneumonia Detection Challenge. It reached mAP@50 = 0.44 with precision 0.44 and recall 0.48 — a useful teaching artifact, far from clinical. Here are three of its validation cases, with ground-truth opacity bboxes overlaid:
The mechanics
A modern YOLO has three components: a CNN backbone (CSPDarknet for v5/v8), a path-aggregation neck (similar in spirit to the FPN), and a Detect head that produces predictions at three feature resolutions.
For a 640×640 input, those three feature maps are at strides 8, 16, and 32:
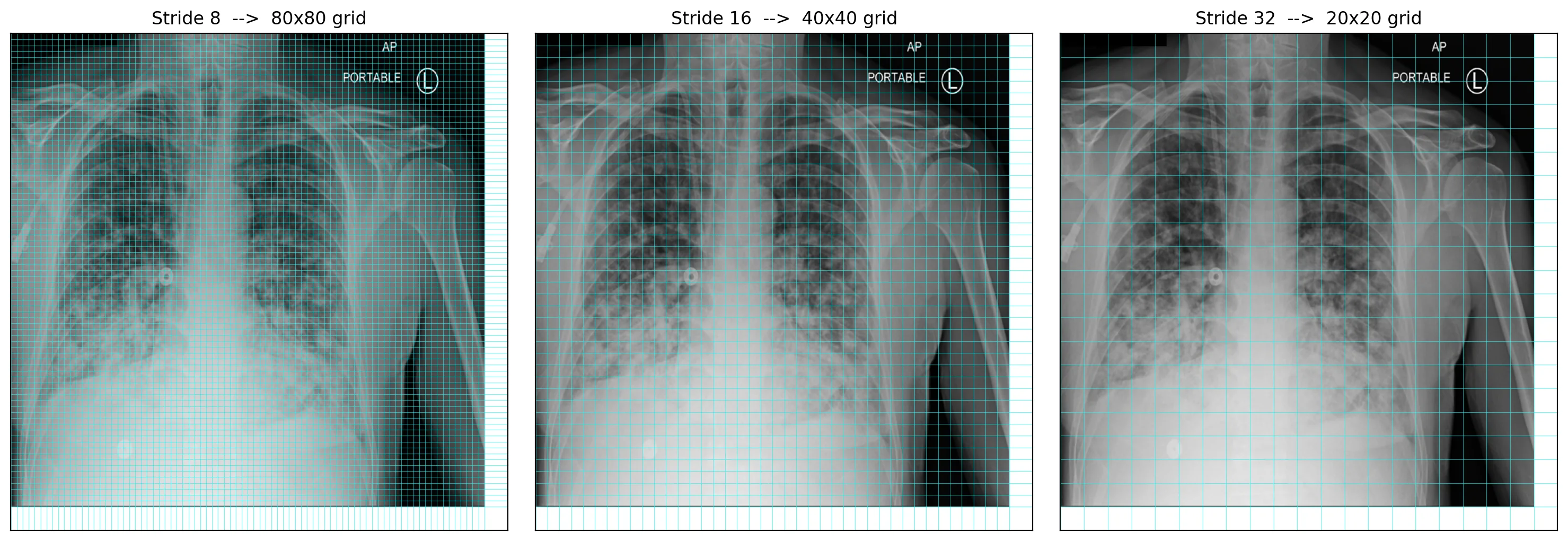
Each cell at each scale produces one set of predictions: four bbox values (center-x, center-y, width, height), one objectness score, and num_classes class scores. With one class (opacity), that's 6 values per cell. Across all three grids the model emits 80² + 40² + 20² = 8,400 candidates per forward pass.
YOLOv1 and v2 were anchor-free. YOLOv3 through v7 introduced anchor priors — pre-defined bounding-box shapes per scale, chosen by k-means over the training boxes — to make regression easier. YOLOv8 returned to anchor-free design with task-aligned assignment: during training each ground-truth box is assigned to whichever predictor across all scales and positions has the best joint classification-plus-localization fit. The choice affects training dynamics and the loss formulation; the inference pipeline looks identical from the outside.
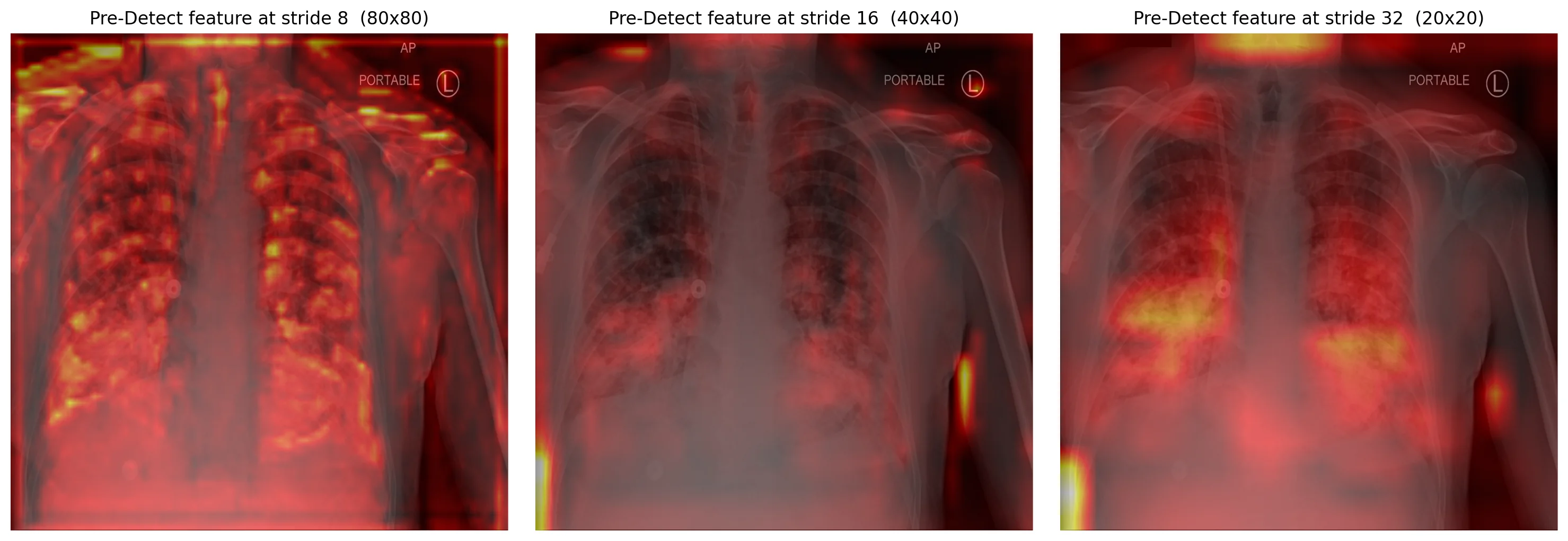
Here are the model's pre-Detect features at the three strides — what each scale "sees" before producing predictions:
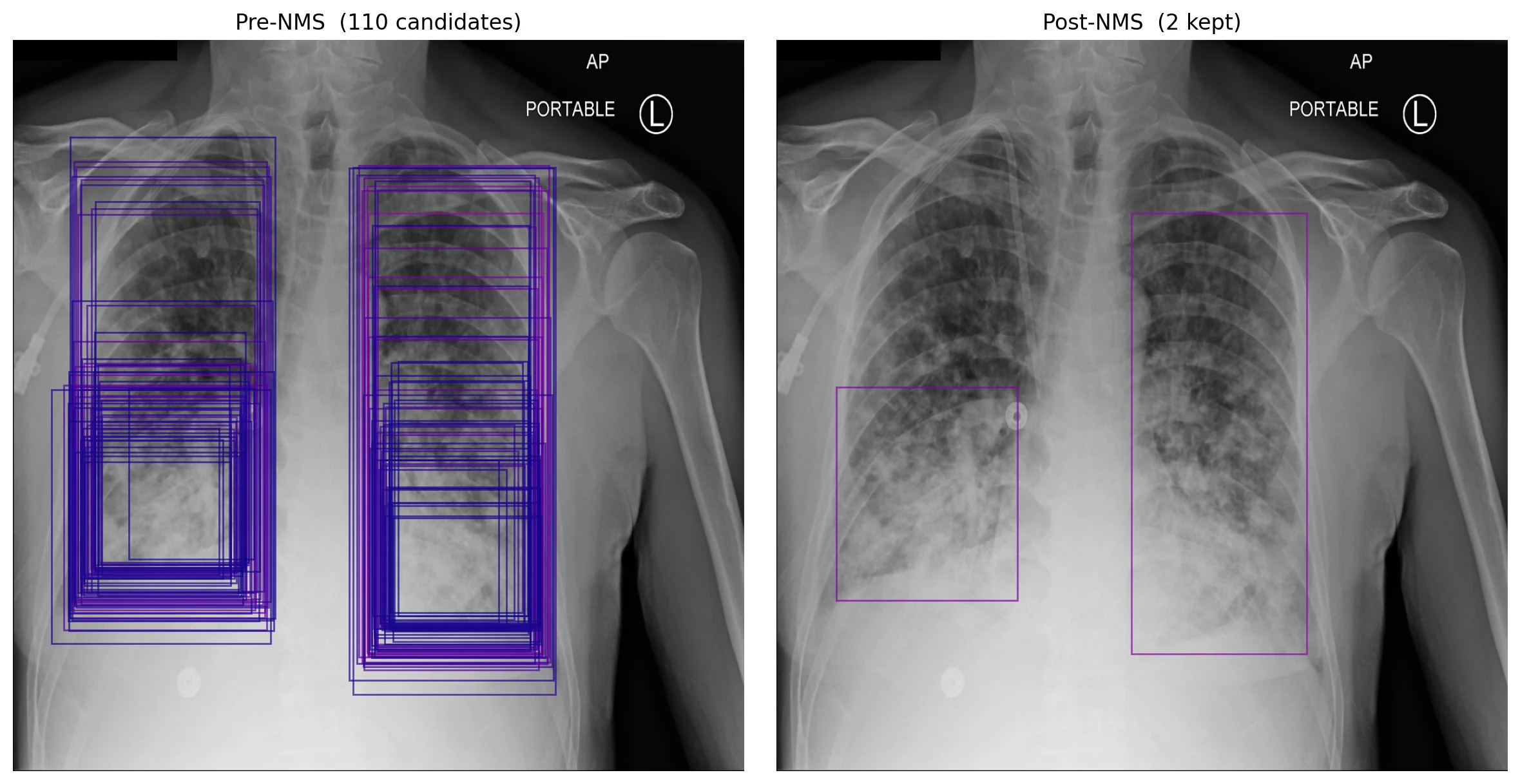
All 8,400 candidates per image are then scored, filtered by confidence, and passed through non-max suppression. NMS sorts boxes by confidence and iteratively suppresses any lower-confidence box whose IoU with a higher-confidence box exceeds a threshold (commonly 0.45 or 0.5). On a typical detection this collapses dozens of overlapping candidates into one box per object:
Where it shines, where it breaks
YOLO shines at real-time, single-class or low-class-count detection where targets are reasonably well-separated. Modern variants give strong results on COCO and adapt well to domain transfer with brief fine-tuning. Per-image inference is fast, batched inference is faster, and the deployment story is uncomplicated.
It breaks in a few predictable places.
Crowded scenes. NMS is greedy. It can't tell whether two highly-overlapping boxes are duplicates of one object or two genuinely separate objects in tight proximity. In medical imaging this hits whenever multiple small lesions overlap, or when bilateral findings sit so close to the mediastinum that their boxes intersect at standard IoU thresholds.
Confidence calibration is poor by default, and brief fine-tuning makes it worse:
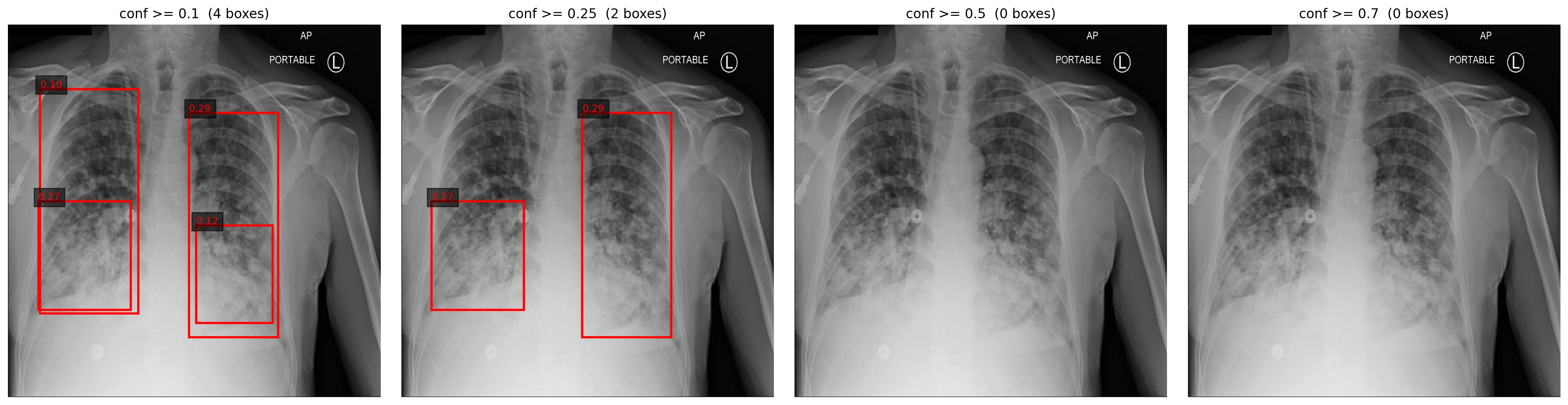
Very small targets relative to grid resolution. A 10-pixel finding in a 640×640 input has to be detected by a cell at stride 8 — the finest scale. If your target is sub-grid-cell, no amount of training fixes that. Increase input resolution before changing the architecture.
How this shows up in production medical-imaging engineering
Stride choice scales with finding size. If your pathology is consistently small relative to the image, increase input resolution rather than tuning hyperparameters. The grid is fixed at strides 8/16/32 for most YOLO variants; the only way to make each cell cover fewer pixels is to feed in a larger image.
NMS thresholds matter, especially with multi-class detection. The default IoU threshold of 0.45 works for COCO-like data with well-separated objects. For dense multi-finding CXR work — multiple infiltrates on one lung, bilateral cardiomegaly indicators near the same anatomy — consider Soft-NMS, or per-class NMS where lung opacity is suppressed independently of pneumothorax.
Augmentation usually matters more than architecture. Once you've picked a YOLO variant, the gains from rotation, brightness and contrast jitter, mosaic, and mixup typically dwarf the gains from swapping yolov8n for yolov8s. Try the simple things first.
Confidence calibration is a separate problem. Don't ship raw confidence as "probability of pathology" without isotonic regression or temperature scaling against a held-out calibration set. The sweep above is what an uncalibrated detector looks like.
Further reading
- Redmon, J. et al. You Only Look Once: Unified, Real-Time Object Detection. CVPR 2016. The original. Short, readable, and the figures clarify the single-stage design better than most explainers.
- Bochkovskiy, A. et al. YOLOv4: Optimal Speed and Accuracy of Object Detection. 2020. A useful survey of the design choices that compound across YOLO versions — backbone, neck, anchor strategy, loss, augmentation.
- Ultralytics YOLOv8 documentation. The practical reference. Worth reading the Tasks/Detect and Modes/Train pages before fine-tuning your own.
Part of an ongoing series on production medical imaging. The CNN-components primer is here; the FPN primer is here; the OBB-vs-axis-aligned deep-dive that motivated this primer is here. If a YOLO detail tripped you up, reach out.